Regresyon
Regresyon Analizi Nedir?
Regresyon analizi, iki ya da daha çok nicel değişken arasındaki ilişkiyi ölçmek için kullanılan analiz metodudur. Eğer tek bir değişken kullanılarak analiz yapılıyorsa buna tek değişkenli regresyon, birden çok değişken kullanılıyorsa çok değişkenli regresyon analizi olarak isimlendirilir. Regresyon analizi ile değişkenler arasındaki ilişkinin varlığı, eğer ilişki var ise bunun gücü hakkında bilgi edinilebilir.
Örneğin; Bir daire satın almayı düşünüyorsunuz. Bu dairenin fiyatını belirleyen birden çok unsur vardır. Örnek:
Toplu taşımaya yakınlığı
Manzarası
Kaçıncı katta olduğu
Binanın yapım yılı
gibi benzeri bir çok unsur binanın fiyatını belirleyen önemli faktörlerdir.
Regresyonda, değişkenlerden biri bağımlı diğerleri bağımsız değişken olmalıdır.
Yapay Sinir Ağı Nedir?
Yapay sinir ağları (YSA), insan beyninin bilgi işleme tekniğinden esinlenerek geliştirilmiş bir bilgi işlem teknolojisidir. YSA ile basit biyolojik sinir sisteminin çalışma şekli taklit edilir. Yani biyolojik nöron hücrelerinin ve bu hücrelerin birbirleri ile arasında kurduğu sinaptik bağın dijital olarak modellenmesidir.
Nöronlar çeşitli şekillerde birbirlerine bağlanarak ağlar oluştururlar. Bu ağlar öğrenme, hafızaya alma ve veriler arasındaki ilişkiyi ortaya çıkarma kapasitesine sahiptirler. Diğer bir ifadeyle, YSA'lar, normalde bir insanın düşünme ve gözlemlemeye yönelik doğal yeteneklerini gerektiren problemlere çözüm üretmektedir. Bir insanın, düşünme ve gözlemleme yeteneklerini gerektiren problemlere yönelik çözümler üretebilmesinin temel sebebi ise insan beyninin ve dolayısıyla insanın sahip olduğu yaşayarak veya deneyerek öğrenme yeteneğidir.
Yapay Sinir Ağlarının Avantajları
Yapay Sinir Ağları bir çok hücreden meydana gelir ve bu hücreler eş zamanlı çalışarak karmaşık işleri gerçekleştirir.
Öğrenme kabiliyeti vardır ve farklı öğrenme algoritmalarıyla öğrenebilirler.
Görülmemiş çıktılar için sonuç (bilgi) üretebilirler. Gözetimsiz öğrenim söz konusudur.
Örüntü tanıma ve sınıflandırma yapabilirler. Eksik örüntüleri tamamlayabilirler.
Hata toleransına sahiptirler. Eksik veya belirsiz bilgiyle çalışabilirler. Hatalı durumlarda dereceli bozulma (graceful degradation) gösterirler.
Paralel çalışabilmekte ve gerçek zamanlı bilgiyi işleyebilmektedirler.
Yapay Sinir Ağlarının Sınıflandırılması
Tek Katmanlı Yapay Sinir Ağları
Tek katmanlı yapay sinir ağları sadece girdi ve çıktı katmanlarından oluşur. Çıktı üniteleri bütün girdi ünitelerine (X) bağlanmaktadır ve her bağlantının bir ağırlığı (W) vardır.
Çok Katmanlı Yapay Sinir Ağları
Doğrusal olmayan problemlerin çözümü için uygun bir ağ yapısıdır. Bu sebeple daha karışık problemlerin çözümünde kullanılır. Karışık problemlerin modeli olması ağın eğitimini zorlaştıran bir yapıya bürünmesine sebep olur. Tek katmanlı ağ yapısına göre daha karmaşık bir yapıdadır. Fakat problem çözümlerinde genellikle çok katmanlı ağ yapısı kullanılır çünkü tek katmanlı yapılara göre daha başarılı sonuçlar verir. Çok katmanlı yapay sinir ağları modellerinde en az 1 adet gizli katman bulunur.
Yapay Sinir Hücresi
Canlılardaki sinir hücrelerinin biyolojik görünümü yukarıda gördüğümüz şekildeki gibidir. Çekirdeğimiz var ve bir akson boyunca iletim yapılıyor. Burada çıkış terminallerinde dentrit uclarından elde edilen sensör verilerimiz çekirdekte ağırlandırılarak akson boyunca iletiliyor ve başka sinir hücresine bağlanıyor. Bu şekilde sinirler arası iletişim sağlanmış oluyor.
İnsandaki bir sinir hücresinin matematiksel modeli ise şu şekilde gösterilebilir:
Dentrit dediğimiz yollar boyunca ağırlıklarımız mevcut ve bu dentritlere giren bir başka nörondan da gelmiş olabilecek bir giriş değerimiz (x0 ) var. Giriş değerimiz ve dentritteki ağırlığımız(w0) çarpıldıktan sonra( w0x0) sinir hücresine iletilir ve sinir hücresinde bu çarpma işlemi yapılıyor ve tüm dentritlerden gelen ağırlık ile giriş çarpımları toplanır. Yani ağırlıklı toplama işlemi yapılır. Ardından bir bias(b) ile toplandıktan sonra aktivasyon fonksiyonu ardından çıkışa aktarılır. Bu çıkış nihai çıkış olabileceği gibi bir başka hücrenin girişi olabilir. Matematiksel olarak ağırlıklar ile girişler çarpılır artı bir bias eklenir. Böylelikle basit bir matematiksel model elde edilir.
Yapay Sinir Ağlarında yapılan temel işlem; modelin en iyi skoru vereceği w(ağırlık parametresi) ve b(bias değeri) parametrelerinin hesabını yapmaktır.
Her bir sinir hücresi aynı şekilde hesaplanır ve bunlar birbirine seri ya da paralel şekilde bağlanır.
Bir yapay sinir hücresi beş bölümden oluşmaktadır;
Girdiler: Girdiler nöronlara gelen verilerdir. Bu girdilerden gelen veriler biyolojik sinir hücrelerinde olduğu gibi toplanmak üzere nöron çekirdeğine gönderilir.
Ağırlıklar: Yapay sinir hücresine gelen bilgiler girdiler üzerinden çekirdeğe ulaşmadan önce geldikleri bağlantıların ağırlığıyla çarpılarak çekirdeğe iletilir. Bu sayede girdilerin üretilecek çıktı üzerindeki etkisi ayarlanabilinmektedir.
Toplama Fonksiyonu (Birleştirme Fonksiyonu): Toplama fonksiyonu bir yapay sinir hücresine ağırlıklarla çarpılarak gelen girdileri toplayarak o hücrenin net girdisini hesaplayan bir fonksiyondur
Aktivasyon fonksiyonu: Önceki katmandaki tüm girdilerin ağırlıklı toplamını alan ve daha sonra bir çıkış değeri (tipik olarak doğrusal olmayan) üreten ve bir sonraki katmana geçiren bir fonksiyondur. (örneğin, ReLU veya sigmoid ).
Çıktılar: Aktivasyon fonksiyonundan çıkan değer hücrenin çıktı değeri olmaktadır. Her hücrenin birden fazla girdisi olmasına rağmen bir tek çıktısı olmaktadır. Bu çıktı istenilen sayıda hücreye bağlanabilir.
Yapay Sinir Ağlarını Bağlantılarına Göre Sınıflandırma
Yapay sinir ağları kendi arasında bağlantılar içerir. Bunlar ileri beslemeli ve geri beslemeli ağlar olarak sınıflandırılırlar.
İleri Beslemeli Ağlar
Tek yönlü bilgi akışı söz konusudur.
Bu ağ modelinde Girdi tabakasından alınan bilgiler Gizli katmana iletilir.
Gizli ve Çıktı tabakalarından bilginin işlenmesi ile çıkış değeri belirlenir.
Geri Beslemeli Ağlar
Bir geri beslemeli sinir ağı, çıkış ve ara katlardaki çıkışların, giriş birimlerine veya önceki ara katmanlara geri beslendiği bir ağ yapısıdır. Böylece, girişler hem ileri yönde hem de geri yönde aktarılmış olur.
Bu çeşit YSA’ların dinamik hafızaları vardır ve bir andaki çıkış hem o andaki hem de önceki girişleri yansıtır. Bundan dolayı, özellikle önceden tahmin uygulamaları için uygundurlar.
Input ve Output Değeri
Yukarıda ki modellemede X ve y arasında ki matematiksel örüntüyü hesaplayabilir misiniz?
Örneğin; X'e 40 değerini verirsek y değeri ne olur ? Ya da y değerini 30 yapan X değeri nedir?
Bunu neden elle (klasik) hesaplayalım. Bu sadece 2 değişkeni olan basit bir yapı. Ya 100 değişkeni olsaydı? O zamanda elle hesaplayabiliriz cümlesini kurabilirmiydik? Tabiki de HAYIR. O zaman bunun için neden bir sinir ağı eğitmiyoruz? Hadi başlayalım...
(<tf.Tensor: shape=(3,), dtype=string, numpy=array([b'bedroom', b'bathroom', b'garage'], dtype=object)>, <tf.Tensor: shape=(1,), dtype=int32, numpy=array([939700], dtype=int32)>)
TensorShape([3])
Tensörde oluşturmayı hatırladığımıza göre şimdi yukarıda bahsettiğimiz X ve y sorununa dair bir sinir ağı eğitelim.
Amacımız kısaca; verilen X değerine göre y değerini bulmak. Burada input değerimiz X, output değerimiz y'dir.
(TensorShape([]), TensorShape([]))
Neden input ve output değerlimizin bir şekli yok.
Bunun nedeni, modelimize ne tür veriler ilettiğimiz önemli değil, her zaman input olarak alacak ve output olarak bir tür tensör olarak geri dönecektir.
Ancak bizim durumumuzda veri kümemiz nedeniyle (sadece 2 küçük sayı listesi), özel bir tür tensöre bakıyoruz, daha spesifik olarak bir rank'ı 0 tensör veya bir skaler.
(<tf.Tensor: shape=(), dtype=float32, numpy=-7.0>, <tf.Tensor: shape=(), dtype=float32, numpy=3.0>)
X[0] = -7.0
y[0] = 3.0 Bir y değerini tahmin etmek için bir X değeri kullanıyoruz. Bu bizim modelimizin en basit denklemi.
Burada anlatmak istediğim nokta; bir input değeri ile output değeri kullanmaktır. Klasik programlama da bir input ve bir fonksiyon kullanarak bir output değeri elde edersiniz. Bizim sinir ağlarında (yada ML) yapmak istediğimiz şey; bir input ve bir output değeri vererek arada ki fonksiyonunu kendi üretmesini istiyoruz.
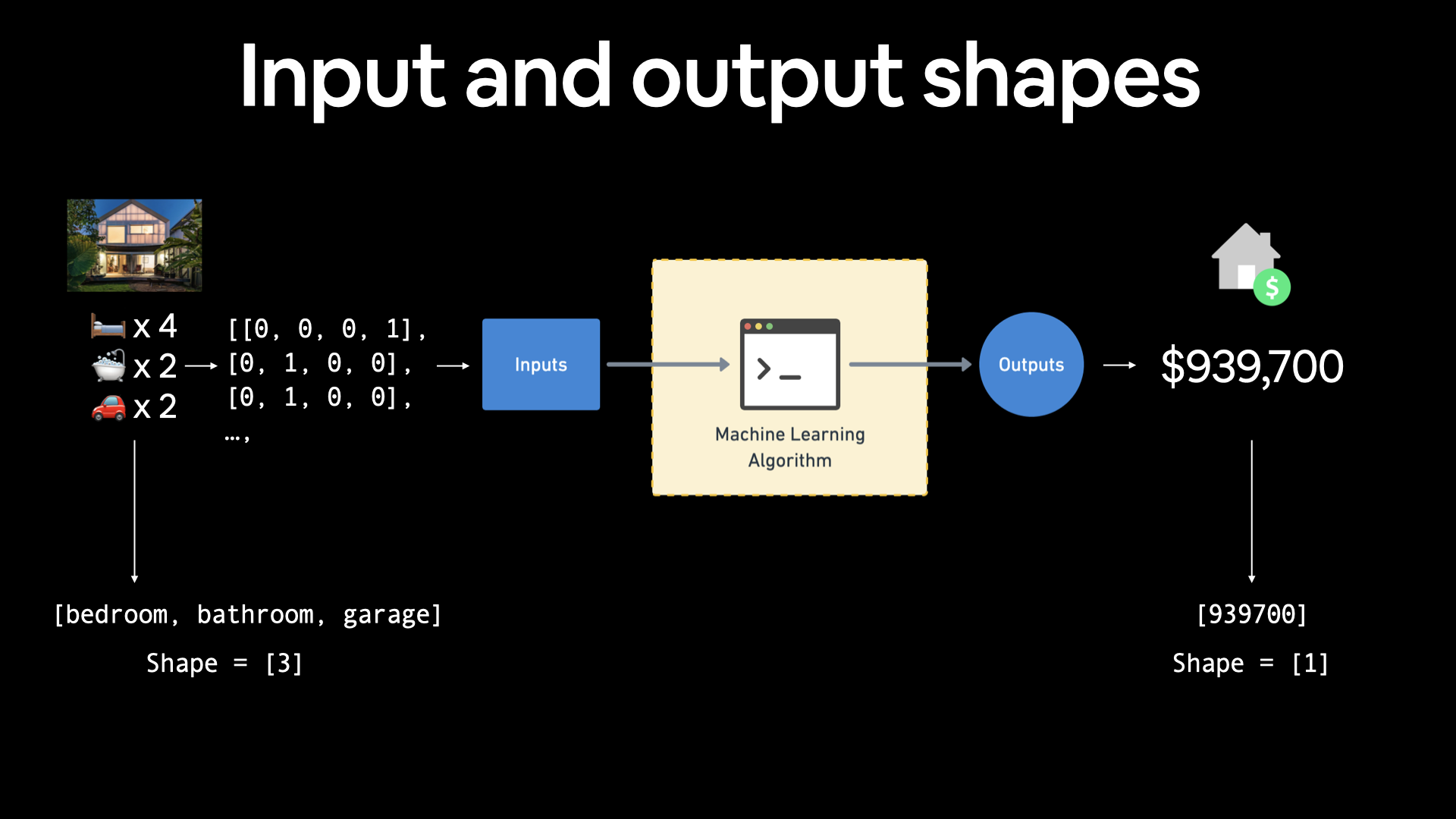
Konut fiyatlarını tahmin etmek için bir makine öğrenimi algoritması oluşturmaya çalışıyorsanız, girdileriniz yatak odası sayısı, banyo sayısı ve garaj sayısı olabilir ve size 3 (3 farklı özellik) girdi şekli verir. Ve evin fiyatını tahmin etmeye çalıştığınız için çıktı şekliniz 1 olur.
Modellemedeki Adımlar
Artık elimizde hangi verilere, girdi ve çıktı şekillerine sahip olduğumuzu biliyoruz, onu modellemek için nasıl bir sinir ağı kuracağımıza bakalım.
TensorFlow'da bir model oluşturmak ve eğitmek için tipik olarak 3 temel adım vardır.
Bir model oluşturma Bir sinir ağının katmanlarını kendiniz bir araya getirin (Functional veya Sequential API'yi kullanarak) veya önceden oluşturulmuş bir modeli içe aktarın (transfer learning olarak bilinir).
Model derleme Bir model performansının nasıl ölçüleceğini (kayıp metrikler) tanımlamanın yanı sıra nasıl iyileştirileceğini (optimize) tanımlama.
Model uydurma Modelin verilerdeki kalıpları bulmaya çalışmasına izin vermek (X, y'ye nasıl ulaşır).
Regresyon verilerimiz için bir model oluşturmak üzere Keras Sequential API'sini kullanarak bunları çalışırken görelim. Ve sonra her birinin üzerinden geçeceğiz.
İşte bu kadar basit :)
X'e bağlı bir y değeri oluşturan bir modeli geliştirdik.
(<tf.Tensor: shape=(8,), dtype=float32, numpy=array([-7., -4., -1., 2., 5., 8., 11., 14.], dtype=float32)>, <tf.Tensor: shape=(8,), dtype=float32, numpy=array([ 3., 6., 9., 12., 15., 18., 21., 24.], dtype=float32)>)
Ama ama bu niye böyle oldu :( Her şeyi doğru yaptık gibi. Modele bir input ve output değeri verdik. Bunu bir sinir ağına bağladık. Fakat doğru sonuçla alakası bile olmayan bir output değeri verdi bize.
Bu soruya cevap vermeden önce size kısa bir soru sormak istiyorum. TensorFlow içerisinde hep Keras dediğimiz yapıları görüyoruz. Bu keras nedir? Cevap
{kind=link}
Bir Model Geliştirmek
Model istediğimiz sonucu vermeyi bırakın, yakınına dahi yanaşamadı. Peki burada çözüm ne?
Doğru tahmin ettiniz. Fine tuning yani ince ayar yapmak. Modeli geliştirmek için hangi adımları uyguladık:
Model oluşturma Burada daha fazla katman eklemek, her katmandaki gizli birimlerin (nöronlar olarak da adlandırılır) sayısını artırmak, her katmanın etkinleştirme işlevlerini değiştirmek isteyebilirsiniz.
Model derleme Optimizasyon fonksiyonunu seçmek veya belki de optimizasyon fonksiyonunun öğrenme oranını değiştirmek isteyebilirsiniz.
Modeli fit etme Daha fazla epoch veya daha fazla veri ile daha iyi sonuçlar almak isteyebilirsiniz.
Vay. Az önce bir dizi olası adımı tanıttık. Hatırlanması gereken önemli şey, bunların her birini nasıl değiştireceğiniz, üzerinde çalıştığınız soruna bağlı olacaktır.
Yukarı da ki kod bloğunu çalıştırdığınızda MAE değerinin yani kayıp fonksiyonun adım adım düştüğünü gözlemleyeceksiniz. İşte bu anda geriye yaslanıp işlemin bitmesini bekleyebilirsiniz çünkü bu doğru gittiğinizi gösteriyor.
Yukarıda 5 epoch ile eğittimizde hiç güzel bir tahmin değeri almadık. Peki ya şimdi?
İşte buuu 💪 0.33 lük bir sapma var ama modelimiz resmen input ve output değerlerini ile doğru eğitilmiş.
Şimdi de modelimizde olmayan bir sayı ile deneme yapalım. Modelimize tekrar göz atalım. Test etmek için arada ki bağlantıyı bulmamız gerekiyor.
(<tf.Tensor: shape=(8,), dtype=float32, numpy=array([-7., -4., -1., 2., 5., 8., 11., 14.], dtype=float32)>, <tf.Tensor: shape=(8,), dtype=float32, numpy=array([ 3., 6., 9., 12., 15., 18., 21., 24.], dtype=float32)>)
-7 --> 3
-4 --> 6
-1 --> 9
Yukarıda ki eşitliklere baktığımızda x + 10 = y gibi bir eşitiğin olduğunu hemen anlayabiliriz. Denklemi çıkardığımıza göre şimdi dizide olmayan bir sayıda nasıl performans gösterdiğini gözlemleyebiliriz.
Hımm. Yaklaşık bir sonuç ama tam da istediğimiz bir cevap değil. Modelimizi bir değerlendirelim daha sonra nasıl daha iyi sonuç alacağımızı düşünürüz.
Modeli Değerlendirme
Sinir ağı oluştururken takip edilen tipik bir akış var:
Fine tuning (ince ayarlama), sıfırdan bir model oluşturmak değil, mevcut bir model üzerinde ayarlamalar yapmaktır.
Modeli değerlendirirken yapılacak en güzel davranışlardan bazıları şunlardır:
Görselleştirin
Görselleştirin
Görselleştirin
Lütfen modeli görselleştirin. Görselleştirmeniz gereken bazı fikirler:
Veriler - hangi verilerle çalışıyorsunuz? Nasıl görünüyor?
Modelin kendisi - mimari neye benziyor? Farklı şekiller nelerdir?
Bir modelin eğitimi - bir model öğrenirken nasıl performans gösterir?
Bir modelin tahminleri - bir modelin tahminleri temel gerçeğe (orijinal etiketler) karşı nasıl sıralanır?
Görselleştirmeyi 1 adım sonraya erteliyoruz çünkü yukarıda eğittiğimiz model tam da istediğimiz sonucu vermedi. Bu yüzden yukarıda ki modeli daha fazla veri ile tekrar eğitmek iyi olabilir.
array([-100, -96, -92, -88, -84, -80, -76, -72, -68, -64, -60, -56, -52, -48, -44, -40, -36, -32, -28, -24, -20, -16, -12, -8, -4, 0, 4, 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48, 52, 56, 60, 64, 68, 72, 76, 80, 84, 88, 92, 96])
array([-90, -86, -82, -78, -74, -70, -66, -62, -58, -54, -50, -46, -42, -38, -34, -30, -26, -22, -18, -14, -10, -6, -2, 2, 6, 10, 14, 18, 22, 26, 30, 34, 38, 42, 46, 50, 54, 58, 62, 66, 70, 74, 78, 82, 86, 90, 94, 98, 102, 106])
x + 10 = y eşitliği sağladık gibi duruyor.
Verileri Train ve Test Olarak Ayırma
Bir makine öğrenimi projesindeki diğer en yaygın ve önemli adımlardan biri, bir eğitim ve test seti (ve gerektiğinde bir doğrulama seti) oluşturmaktır.
Her set belirli bir amaca hizmet eder:
Eğitim seti Model, genellikle mevcut toplam verilerin (epoch boyunca çalıştığınız ders materyalleri gibi) %70-80'i olan bu verilerden öğrenir.
Doğrulama seti Model, genellikle mevcut toplam verilerin %10-15'i olan bu verilere göre ayarlanır (final sınavından önce girdiğiniz alıştırma sınavı gibi).
Test seti Model, öğrendiklerini test etmek için bu veriler üzerinde değerlendirilir, genellikle mevcut toplam verilerin %10-15'i kadardır (dönem sonunda girdiğiniz final sınavı gibi).
Şimdilik sadece bir eğitim ve test seti kullanacağız, bu, modelimizin öğrenilmesi ve değerlendirilmesi için bir veri setimiz olacağı anlamına geliyor.
X ve y dizilerimizi bölerek bunları oluşturabiliriz.
🔑 Not: Gerçek dünya verileriyle uğraşırken, bu adım tipik olarak bir projenin hemen başlangıcında yapılır (test seti her zaman diğer tüm verilerden ayrı tutulmalıdır). Modelimizin eğitim verilerini öğrenmesini ve ardından görünmeyen örneklere ne kadar iyi genelleştiğine dair bir gösterge elde etmek için test verileri üzerinde değerlendirmesini istiyoruz.
50
(40, 10)
Verileri Görselleştirme
Artık eğitim ve test verilerimiz var, artık bunu görselleştirmek iyi bir fikir.
Neyin ne olduğunu ayırt etmek için güzel renklerle çizelim.
Güzel! Verilerinizi, modelinizi, herhangi bir şeyi görselleştirebildiğiniz her an, bu iyi bir fikirdir.
Bu grafiği göz önünde bulundurarak, yeşil noktaları (X_test) çizmek için mavi noktalardaki (X_train) deseni öğrenen bir model oluşturmaya çalışacağız.
Modeli Görselleştirme
Bir model oluşturduktan sonra, ona bir göz atmak isteyebilirsiniz (özellikle daha önce çok model oluşturmadıysanız).
Modelinizin katmanlarını ve şekillerini, üzerinde Summary()'i arayarak inceleyebilirsiniz.
🔑 Not: Bir modeli görselleştirmek, özellikle girdi ve çıktı şekli uyumsuzluklarıyla karşılaştığınızda faydalıdır.
ValueError
Sizce yukarıda ki hatanın sebebi modeli fit etmememiz mi? Hımm. Hata mesajını okuduğumuzda input_shape değerinin olmadığını söylüyor.
Input_shape değeri ilk katmana girilir. Şimdi deneyelim ve bakalım hata gideriliyor mu?
Modelimizde summary() işlevini çağırmak bize içerdiği katmanları, çıktı şeklini ve parametre sayısını gösterir.
Toplam parametreler Modeldeki toplam parametre sayısı.
Eğitilebilir parametreler Bunlar, modelin eğitirken güncelleyebileceği parametrelerdir (kalıplardır).
Eğitilemez parametreler Bu parametreler eğitim sırasında güncellenmez (bu, transfer learninig sırasında diğer modellerden önceden öğrenilmiş kalıpları getirdiğinizde tipiktir).
📖 Kaynak: Bir katmandaki eğitilebilir parametrelere daha derinlemesine bir genel bakış için MIT'nin derin öğrenme videosuna girişine göz atın.
🛠 Alıştırma: Dense katmandaki gizli birimlerin sayısıyla oynamayı deneyin (örn.
Dense(2),Dense(3)). Bu, Toplam/Eğitilebilir parametreleri nasıl değiştirir? Değişikliğe neyin sebep olduğunu araştırın.
Şimdilik, bu parametreler hakkında düşünmeniz gereken tek şey, bunların verilerdeki öğrenilebilir kalıplarıdır.
Modelimizi eğitim verileriyle fir edelim şimdi.
Özetin yanı sıra plot_model() kullanarak modelin 2D grafiğini de görüntüleyebilirsiniz.
Bizim durumumuzda, kullandığımız modelin yalnızca bir girdisi ve bir çıktısı var, ancak daha karmaşık modelleri görselleştirmek hata ayıklama için çok yardımcı olabilir.
Tahminleri Görselleştirme
Şimdi eğitilmiş bir modelimiz var, hadi bazı tahminleri görselleştirelim.
Tahminleri görselleştirmek için, onları temel gerçek etiketlerine göre planlamak her zaman iyi bir fikirdir.
Bunu genellikle y_test ve y_pred (gerçek ve tahminler) şeklinde görürsünüz.
İlk olarak, test verileri (X_test) üzerinde bazı tahminler yapacağız, modelin test verilerini hiç görmediğini unutmayın.
array([[53.57109 ], [57.05633 ], [60.541573], [64.02681 ], [67.512054], [70.99729 ], [74.48254 ], [77.96777 ], [81.45301 ], [84.938255]], dtype=float32)
Bunları gerçek değerler ile karşılaştırıp modelin doğruluğunu anlamak için bir fonksiyon yaratalım:
Tahminleri Değerlendirme
Görselleştirmelerin yanı sıra değerlendirme metrikleri, modelinizi değerlendirmek için alternatif en iyi seçeneğinizdir.
Üzerinde çalıştığınız soruna bağlı olarak, farklı modellerin farklı değerlendirme ölçütleri vardır.
Regresyon problemleri için kullanılan ana metriklerden ikisi şunlardır:
Mean absolute error (MAE) Tahminlerin her biri arasındaki ortalama fark.
Mean squared error (MSE) Tahminler arasındaki kare ortalama fark.
Bu değerlerin her biri ne kadar düşükse, o kadar iyidir.
Ayrıca, derleme adımı sırasında herhangi bir ölçüm ayarının yanı sıra modelin kaybını döndürecek olan model.evaluate() öğesini de kullanabilirsiniz.
[18.74532699584961, 18.74532699584961]
Biz MAE(metrics=['MAE']) değerini kullandığımız için evaluate fonksiyonu bize MAE değerini döndürecektir.
TensorFlow'da ayrıca MSE ve MAE için ayrı olarak fonksiyonlar vardır. Bunlar değerlendirme için ayrıca kullanılabilir.
<tf.Tensor: shape=(10,), dtype=float32, numpy= array([34.42891 , 30.943668, 27.45843 , 23.97319 , 20.487946, 17.202168, 14.510478, 12.419336, 11.018796, 10.212349], dtype=float32)>
Aaa. Neden bir çıktı yerine on farklı çıktı aldık?
Bunun nedeni, y_test ve y_preds tensorlerinin farklı şekillerde olmasından kaynaklanıyor.
array([ 70, 74, 78, 82, 86, 90, 94, 98, 102, 106])
array([[53.57109 ], [57.05633 ], [60.541573], [64.02681 ], [67.512054], [70.99729 ], [74.48254 ], [77.96777 ], [81.45301 ], [84.938255]], dtype=float32)
((10,), (10, 1))
Hatırlarsanız en başta Input ve Outpu değerlerini konuşmuşduk. Ve o sorun geldi çattı. Bu değerlerin aynı şekillere sahip olmasoı gerekiyor yoksa değerlendirmemiz imkansız.
squeeze() kullanarak bunu düzeltebiliriz, 1 boyutunu y_preds tensörümüzden kaldıracak ve onu y_test ile aynı şekle getirecektir.
(10, 1)
(10, )
(array([ 70, 74, 78, 82, 86, 90, 94, 98, 102, 106]), array([53.57109 , 57.05633 , 60.541573, 64.02681 , 67.512054, 70.99729 , 74.48254 , 77.96777 , 81.45301 , 84.938255], dtype=float32))
Tamamdır, şimdi y_test ve y_preds tensorlerımızı nasıl aynı şekle getireceğimizi biliyoruz, hadi değerlendirme metriklerimizi kullanalım.
(<tf.Tensor: shape=(), dtype=float32, numpy=18.745327>, <tf.Tensor: shape=(), dtype=float32, numpy=353.57336> )
MAE'yi saf TensorFlow işlevlerini kullanarak da hesaplayabiliriz.
<tf.Tensor: shape=(), dtype=float64, numpy=18.745327377319335>
Yine, tekrar kullanabileceğinizi (veya kendinizi tekrar tekrar kullanırken bulabileceğinizi) düşündüğünüz herhangi bir şeyi işlevsel hale getirmek iyi bir fikirdir.
Değerlendirme metriklerimiz için fonksiyonlar yaratalım
Bir Modeli Geliştirmek İçin Denemeler Yapmak
Değerlendirme metriklerini ve modelinizin yaptığı tahminleri gördükten sonra, muhtemelen modeli geliştirmek isteyeceksiniz.
Yine, bunu yapmanın birçok farklı yolu vardır, ancak bunlardan başlıca 3 tanesi şunlardır:
Daha fazla veri elde edin Modeliniz için daha fazla örnek alın (kalıpları öğrenmek için daha fazla fırsat).
Modelinizi büyütün (daha karmaşık bir model kullanın) Bu, her katmanda daha fazla katman veya daha fazla gizli birim şeklinde olabilir.
Daha uzun süre eğitin Modelinize verilerdeki kalıpları bulma şansı verin.
Veri kümemizi oluşturduğumuzdan, kolayca daha fazla veri üretebiliyorduk, ancak gerçek dünya veri kümeleriyle çalışırken durum her zaman böyle olmuyor.
Şimdi 2 ve 3'ü kullanarak modelimizi nasıl geliştirebileceğimize bir göz atalım.
Bunu yapmak için 3 model oluşturacağız ve sonuçlarını karşılaştıracağız:
model_1- orijinal modelle aynı, 1 katman, 100 epoch için eğitilmiş.model_2- 100 epoch için eğitilmiş 2 katman.model_3- 500 epoch için eğitilmiş 2 katman.
Model_1
(18.745327, 353.57336)
model_2
Bu sefer ekstra yoğun bir katman ekleyeceğiz (böylece artık modelimiz 2 katmana sahip olacak), diğer her şeyi aynı tutacağız.
Çoook iyi. Tek gereken şey ekstradan bir katmanmış.
(1.9098114, 5.459232)
model_3
3.modelimiz için her şeyi model_2 ile aynı tutacağız, ancak bu sefer daha uzun train edeceğiz (100 yerine 500 epoch).
Bu, modelimize verilerdeki kalıpları öğrenme şansı verecektir.
Modeli görselleştirmeden önce epoch terimini anlatmadığımı fark ettim. Şuan çokca kullanıyoruz ve bilmemeniz neden sonucun değiştiğini anlamanızı zorlaştırabilir.
Kısaca epoch, eğitim sırasında tüm eğitim verilerinin ağa gösterilme sayısıdır. Daha fazla ayrıntı için bu yazıyı okuyabilirsiniz.
Amaa daha iyi olması gerekmiyor muydu modelin?
Görünen o ki, modelimiz çok uzun süre eğitilmiş ve bu nedenle daha kötü sonuçlara yol açmış olabilir (daha sonra eğitimi çok uzun süre engellemenin yollarını göreceğiz).
(68.68786, 4804.4717)
Sonuçları Karşılaştırma
En iyi performansı model_2 gösteriyor.
Ve şimdi, "modelleri karşılaştırmak sıkıcı..." diye düşünebilirsiniz ama burada sadece 3 modeli karşılaştırdık.
Ancak bu, birçok farklı model kombinasyonunu denemek ve hangisinin en iyi performansı gösterdiğini görmek, makine öğrenimi modellemesinin neyle ilgili olduğunun bir parçasıdır.
Oluşturduğunuz her model küçük bir deneydir.
🔑 Not: Ana hedeflerinizden biri, deneyleriniz arasındaki süreyi en aza indirmek olmalıdır. Ne kadar çok deney yaparsanız, hangilerinin işe yaramadığını o kadar çok anlarsınız ve sırayla neyin işe yaradığını bulmaya yaklaşırsınız. Makine öğrenimi uygulayıcısının sloganını hatırlayın: "deney, deney, deney".
Ayrıca bulacağınız başka bir şey de işe yarayacağını düşündüğünüz şeyin (bir modeli daha uzun süre eğitmek gibi) her zaman işe yaramayabilir ve çoğu zaman tam tersi de geçerlidir.
Denemelerinizi izleme
Hangisinin diğerlerinden daha iyi performans gösterdiğini görmek için modelleme deneylerinizi takip etmek, gerçekten iyi bir alışkanlıktır.
Yukarıda bunun basit bir versiyonunu yaptık (sonuçları farklı değişkenlerde tutarak).
📖 Kaynak: Ancak daha fazla model oluşturduğunuzda, aşağıdaki gibi araçları kullanmak isteyeceksiniz:
TensorBoard TensorFlow kitaplığının modelleme deneylerini izlemeye yardımcı olan bir bileşeni (bunu daha sonra göreceğiz).
Weights & Biases Her türlü makine öğrenimi deneyini izlemek için bir araç.
Bir Modeli Kaydetme
Bir modeli eğittiğinizde ve beğeninize uygun bir model bulduğunuzda, muhtemelen onu başka bir yerde (bir web uygulaması veya mobil cihaz gibi) kullanmak üzere kaydetmek isteyeceksiniz.
model.save() kullanarak bir TensorFlow/Keras modelini kaydedebilirsiniz.
TensorFlow'da bir modeli kaydetmenin iki yolu vardır:
SavedModel biçimi (varsayılan).
HDF5 formatı.
İkisi arasındaki temel fark, SavedModel'in, modeli tekrar yüklerken ek değişiklikler yapmadan özel nesneleri (özel katmanlar gibi) otomatik olarak kaydedebilmesidir.
Hangisini kullanmalısınız?
Durumunuza bağlıdır ancak SavedModel formatı çoğu zaman yeterli olacaktır.
Her iki yöntem de aynı yöntem çağrısını kullanır.
assets keras_metadata.pb saved_model.pb variables
Şimdi modeli HDF5 formatında kaydedelim, aynı yöntemi kullanacağız ama farklı bir dosya adıyla.
best_model_HDF5_format.h5
Modeli Yükleme
load_model() yöntemini kullanarak kaydedilmiş bir modeli yükleyebiliriz.
Farklı biçimler (SavedModel ve HDF5) için bir model yüklemek aynıdır (belirli biçimlerin yol adları doğru olduğu sürece).
True
true
Daha Büyük Bir Örnek
Pekala, TensorFlow'da sinir ağı regresyon modelleri oluşturmanın temellerini gördük.
Bir adım öteye gidelim ve daha zengin özelliklere sahip bir veri için bir model oluşturalım.
Daha spesifik olarak, yaş, cinsiyet, vücut ağırlığı, çocuklar, sigara içme durumu ve yerleşim bölgesi gibi bir dizi farklı parametreye dayalı olarak bireyler için sağlık sigortası maliyetini tahmin etmeye çalışacağız.
Bunu yapmak için, Kaggle'da bulunan ve GitHub'da barındırılan, herkesin kullanımına açık Tıbbi Maliyet veri kümesinden yararlanacağız.
Sayısal olmayan sütunları sayısal tipe çevirmemiz gerekecek (çünkü bir sinir ağı sayısal olmayan girdileri işleyemez).
Bunu yapmak için pandas get_dummies() yöntemini kullanacağız.
One-hot encoding kullanarak kategorik değişkenleri (cinsiyet, sigara içen ve bölge sütunları gibi) sayısal değişkenlere dönüştürür.
Şimdi verileri özellikler (X) ve etiketler (y) olarak ayıracağız.
Ve eğitim ve test setleri oluşturun. Bunu manuel olarak yapabiliriz, ancak kolaylaştırmak için Scikit-Learn'de zaten mevcut olan train_test_split işlevinden yararlanacağız.
Şimdi bir model oluşturup fitleyebiliriz (bunu model_2 ile aynı yapacağız).
[8628.2392578125, 8628.2392578125]
Modelimiz pek iyi performans göstermedi, hadi daha büyük bir model ile tekrar deneyelim.
3 şey deneyeceğiz:
Katman sayısını artırma (2 -> 3).
Her katmandaki birim sayısını artırma (çıktı katmanı hariç)
Optimize ediciyi değiştirme (SGD'den Adam'a).
Diğer her şey aynı kalacak.
[4924.34765625, 4924.34765625]
Çok daha iyi! Daha büyük bir model ve Adam optimize edici kullanmak, önceki modele göre neredeyse yarı yarıya hatayla sonuçlanır.
🔑 Not: Birçok sorun için Adam optimize edici harika bir başlangıç seçimidir. Daha fazlası için A Recipe for Training Neural Networks
Modelimizin kayıp eğrilerine bir göz atalım, aşağı yönlü bir trend görmeliyiz.
Buradan, modelimizin kaybının (ve MAE) her ikisinin de hala azalmakta olduğu görülüyor (bizim durumumuzda, MAE ve kayıp aynı, dolayısıyla çizgiler birbiriyle örtüşüyor).
Bunun bize söylediği şey, onu daha uzun süre eğitmeye çalışırsak kaybın düşebileceğidir.
🤔 Soru: Ne kadar süre eğitim yapmalısınız?
Hangi sorun üzerinde çalıştığınıza bağlı. Bazen eğitim çok uzun sürmez, bazen beklediğinizden daha uzun sürer. Yaygın bir yöntem, model eğitiminizi çok uzun bir süre için ayarlamaktır (ör. 1000'lerce epoch), ancak bunu bir EarlyStopping callback değeri ile ayarlamaktır, böylece gelişmeyi bıraktığında otomatik olarak durur. Bunu başka bir eğitimde göreceğiz.
Yukarıdaki modeli biraz daha uzun süre eğitelim.
(3494.728515625, 3494.728515625)
Başardık! Fazladan 100 epoch eğitim, hatada yaklaşık %10'luk bir azalma görüyoruz.
Ön İşleme Verileri (normalleştirme ve standardizasyon)
Sinir ağlarıyla çalışırken yaygın bir uygulama, onlara ilettiğiniz tüm verilerin 0 ila 1 aralığında olduğundan emin olmaktır.
Bu uygulamaya normalleştirme denir (tüm değerleri orijinal aralıklarından 0 ile 100.000 arasında 0 ile 1 arasında olacak şekilde ölçeklendirmek).
Tüm verilerinizi birim varyansa ve 0 ortalamaya dönüştüren başka bir işlem çağrısı standardizasyonu vardır.
Bu iki uygulama genellikle bir ön işleme hattının (verilerinizi sinir ağlarıyla kullanıma hazırlamak için bir dizi işlev) parçasıdır.
Bunu bilerek, bir sinir ağı için verilerinizi önceden işlemek üzere atacağınız bazı önemli adımlardan bazıları şunlardır:
Tüm verilerinizi sayılara çevirmek (bir sinir ağı dizeleri işleyemez).
Verilerinizin doğru şekilde olduğundan emin olun (giriş ve çıkış şekillerini doğrulama).
Özellik ölçeklendirme:
Verileri normalleştirme (tüm değerlerin 0 ile 1 arasında olduğundan emin olun). Bu, minimum değerin çıkarılması ve ardından maksimum değerin minimumdan çıkarılmasıyla yapılır. Bu aynı zamanda min-maks ölçekleme olarak da adlandırılır.
Standardizasyon (tüm değerlerin ortalamasının 0 ve varyansının 1 olduğundan emin olun). Bu, ortalama değerin hedef özellikten çıkarılması ve ardından standart sapmaya bölünmesiyle yapılır.
Hangisini kullanmalısınız?
Sinir ağlarında, 0 ile 1 arasındaki değerleri tercih etme eğiliminde oldukları için normalleştirmeyi tercih edeceksiniz (bunu özellikle görüntü işlemede göreceksiniz), ancak genellikle bir sinir ağının minimum özellik ölçekleme ile oldukça iyi performans gösterebileceğini göreceksiniz.
📖 Kaynak: Ön işleme verileri hakkında daha fazla bilgi için aşağıdaki kaynakları okumanızı tavsiye ederim:
Verilerimizi get_dummies() kullanarak zaten sayılara dönüştürdük, nasıl normalleştireceğimize de bakalım.
Şimdi, daha önce olduğu gibi, sayısal olmayan sütunları sayılara dönüştürmemiz gerekiyor ve bu sefer de sayısal sütunları farklı aralıklarla normalleştireceğiz (hepsinin 0 ile 1 arasında olduğundan emin olmak için).
Bunu yapmak için Scikit-Learn'den birkaç sınıf kullanacağız:
make_column_transformer - aşağıdaki dönüşümler için çok adımlı bir veri ön işleme işlevi oluşturun:
MinMaxScaler - tüm sayısal sütunların normalleştirildiğinden emin olun (0 ile 1 arasında).
OneHotEncoder - sayısal olmayan sütunları kodlar.
Verilerimiz şimdi nasıl görünüyor?
array([0.60869565, 0.10734463, 0.4 , 1. , 0. , 1. , 0. , 0. , 1. , 0. , 0. ])
((1070, 11), (1070, 6))
Verilerimiz normalize edilmiş ve sayısaldır, hadi modelleyelim.
insurance_model_2 ile aynı modeli kullanacağız.
Ve son olarak, insurance_model_2 (normalleştirilmemiş veriler üzerinde eğitilmiş) ve insurance_model_3 (normalleştirilmiş veriler üzerinde eğitilmiş) sonuçlarını karşılaştıralım.
Bundan, verileri normalleştirmenin, aynı modeli kullanarak verileri normalleştirmemeye göre %10 daha az hatayla sonuçlandığını görebiliriz.
Bu, normalleştirmenin ana faydalarından biridir: daha hızlı yakınsama süresi (söylemenin süslü bir yolu, modeliniz daha hızlı daha iyi sonuçlara ulaşır).
insurance_model_2, eğitimini daha uzun süre bırakırsak, sonunda insurance_model_3 ile aynı sonuçları elde etmiş olabilir.
Ayrıca, modellerin mimarilerini değiştirecek olursak sonuçlar değişebilir, örn. katman veya daha fazla katman başına daha fazla gizli birim.
Ancak sinir ağı uygulayıcıları olarak asıl amacımız deneyler arasındaki süreyi azaltmak olduğundan, daha iyi sonuçları daha erken almamıza yardımcı olan her şey bir artıdır.
Last updated